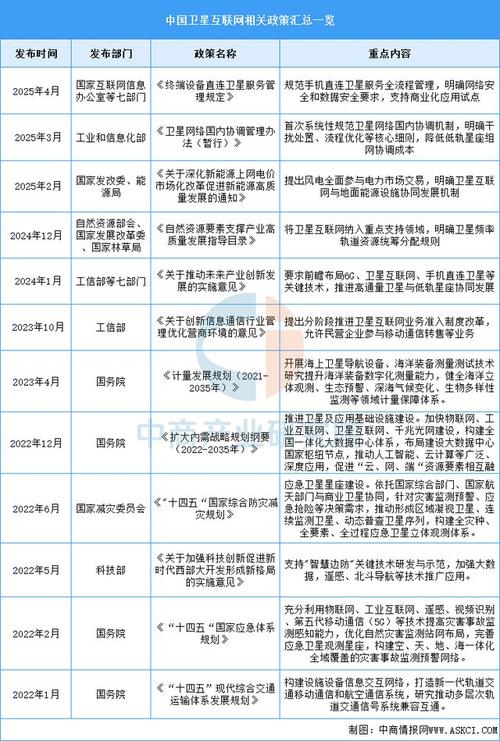
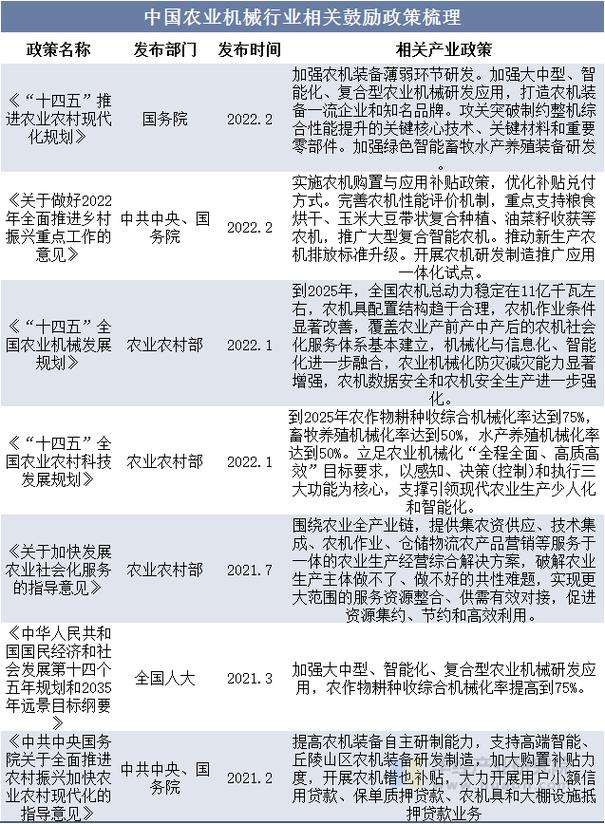
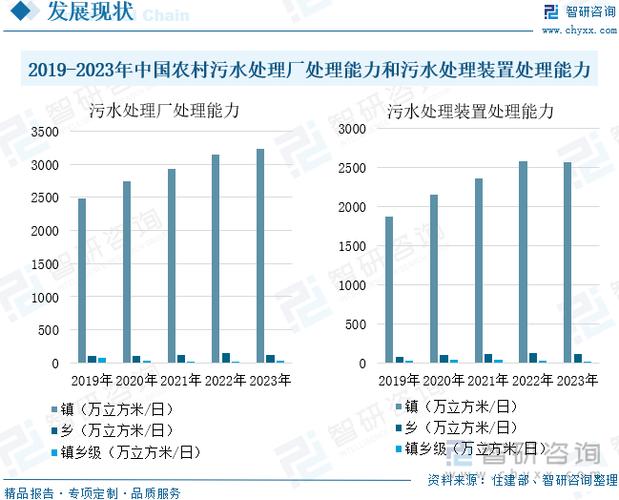
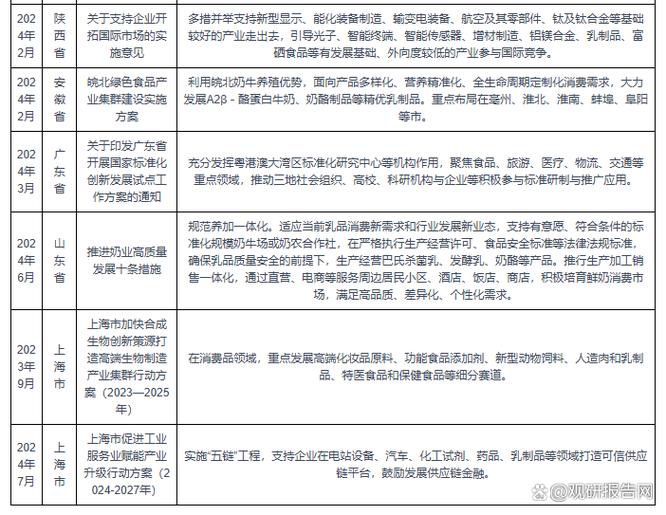
ACS数据如何真实反映政策执行情况?
 摘要:
下面我将从“为什么用ACS”、“如何评估”、“具体案例”以及“局限性”四个方面,系统地阐述如何从ACS数据看政策执行情况, 为什么ACS是评估政策执行的理想数据源?在深入方法之前,...
摘要:
下面我将从“为什么用ACS”、“如何评估”、“具体案例”以及“局限性”四个方面,系统地阐述如何从ACS数据看政策执行情况, 为什么ACS是评估政策执行的理想数据源?在深入方法之前,... 下面我将从“为什么用ACS”、“如何评估”、“具体案例”以及“局限性”四个方面,系统地阐述如何从ACS数据看政策执行情况。
(图片来源网络,侵删)
为什么ACS是评估政策执行的理想数据源?
在深入方法之前,我们首先要明白ACS数据的独特优势:
- 样本量巨大:ACS每年调查约350万个家庭,数据覆盖美国几乎所有地理区域,小到城市街区、普查区,大到州、国家,这使得我们能够精确地检测到政策干预后细微的变化,尤其是在地方层面。
- 变量极其丰富:ACS包含超过100个数据主题,涵盖人口、社会、经济、住房等多个维度,它详细记录了收入、贫困率、教育水平、就业状况、医疗保险覆盖、住房成本、通勤方式等,这些几乎可以对应到任何一项社会或经济政策的评估指标。
- 更新频率高:ACS每年发布1年期的估计数据(对于较大地理区域)和5年期的估计数据(对于较小地理区域),相比于十年一次的人口普查,它能够提供近乎实时的政策效果反馈,允许政策制定者进行动态调整。
- 地理颗粒度细:数据可以精细到普查区层面,这对于评估“精准滴灌”式的、针对特定社区或人群的政策(如社区发展补助金、学区改革)至关重要。
如何从ACS数据评估政策执行情况?
评估政策执行情况,通常遵循一个清晰的逻辑框架:“政策目标 → 理论机制 → 数据指标 → 结果比较”。
第一步:明确政策目标与理论机制
任何政策都有其目标,我们需要将抽象的政策目标转化为可衡量的具体指标。
- 政策目标:“提高低收入家庭的可负担能力”。
- 理论机制:政策如何实现这个目标?“通过向低收入家庭提供住房补贴,降低其住房支出占收入的比例”。
- 可衡量指标:根据理论机制,从ACS数据中找到对应的变量。
- 因变量:住房成本占家庭收入的比例 (
GROSS RENT AS A PERCENTAGE OF HOUSEHOLD INCOME或SELECTED MONTHLY OWNER COSTS AS A PERCENTAGE OF HOUSEHOLD INCOME)。 - 自变量/分组变量:是否获得住房补贴(可以通过家庭收入、住房类型等间接识别或结合其他数据源)。
- 控制变量:家庭规模、户主年龄、教育水平、种族等,这些因素也会影响住房成本。
- 因变量:住房成本占家庭收入的比例 (
第二步:构建“处理组”与“控制组”
这是评估政策效果的核心,为了证明政策是导致变化的原因,我们需要进行比较。

(图片来源网络,侵删)
- 处理组:政策目标覆盖的人群或地区,某市实施了新的“就业培训计划”,处理组就是参加了该计划的居民。
- 控制组:与处理组相似,但没有受到政策直接影响的人群或地区,该市其他未参加培训计划的居民,或者一个与该市特征相似但未实施该计划的城市。
关键点:控制组的选择至关重要,必须尽可能保证在政策实施前,处理组和控制组在各项特征上具有可比性。
第三步:选择合适的ACS数据产品和时间窗口
- 数据产品:
- 1年期ACS数据:适合评估覆盖范围广、影响大的国家级或州级政策,时效性强。
- 5年期ACS数据:适合评估地方性、小范围的政策,因为样本量更大,地理颗粒度更细(到街区层面),但时效性较差(2025-2025年的5年数据发布于2025年)。
- 时间窗口:需要比较政策实施前后的数据。
- 政策前:政策在2025年实施,我们可以使用2025年或2025年的ACS数据作为基线。
- 政策后:使用2025年或2025年的ACS数据作为结果。
第四步:进行数据分析与比较
通过比较处理组和控制组在政策前后的指标变化,来评估政策的执行效果。
-
描述性统计:
- 计算政策前后,处理组和控制组的核心指标(如平均收入、贫困率)的均值、中位数。
- 观察变化趋势:处理组的指标是否朝着政策预期的方向变化?变化的幅度有多大?
-
差异-in-差异法:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 这是一种更严谨的准实验研究方法。
- 公式:
政策效果 = (处理组后 - 处理组前) - (控制组后 - 控制组前) - 解释:这个结果排除了宏观趋势(如全国性经济复苏)对处理组和控制组的共同影响,从而更准确地估计政策的净效应。
-
回归分析:
- 建立多元回归模型,控制其他混杂因素,精确估计政策的影响。
- 模型示例:
Y = β₀ + β₁*Policy + β₂*X₁ + β₃*X₂ + ... + εY是结果变量(如收入)。Policy是一个虚拟变量(1=处理组,0=控制组)。X₁, X₂...是控制变量(如年龄、教育)。- 就是我们要找的政策效应系数。
具体案例:评估“平价医疗法案”对医疗保险覆盖的影响
ACA于2010年签署,核心目标是降低无保险率。
- 政策目标:减少美国无医疗保险的人口数量。
- 理论机制:通过扩大医疗补助和提供健康保险补贴,让更多人获得保险。
- 数据指标:
- 核心指标:无医疗保险的人口比例 (
NO HEALTH INSURANCE COVERAGE)。 - 分组变量:各州,因为各州是否扩大医疗补助(ACA的一项关键条款)是自愿的,这为我们提供了天然的“处理组”(扩大医疗补助的州)和“控制组”(未扩大的州)。
- 核心指标:无医疗保险的人口比例 (
- 数据与时间:
- 政策前:使用2008-2010年的ACS 5年期数据。
- 政策后:使用2025-2025年的ACS 5年期数据(ACA主要条款在2025年生效)。
- 分析结果:
- 描述性比较:在2025年后,扩大医疗补助的州的“无保险率”下降幅度,显著大于未扩大的州。
- DID分析:计算结果显示,在控制了经济、人口等因素后,医疗补助扩张使得州的“无保险率”平均下降了约3-5个百分点,这个结果有力地证明了ACA在扩大保险覆盖方面的政策执行是有效的。
使用ACS数据评估政策的局限性
尽管ACS功能强大,但在使用时也必须清醒认识其局限性:
- 相关性不等于因果性:这是所有观察性数据的通病,即使我们发现A和B相关,也不能100%断定是A导致了B,可能存在未观测到的混杂因素,DID和回归分析是缓解此问题的工具,但无法完全根除。
- 抽样误差:ACS是抽样调查,不是普查,所有数据都是估计值,存在置信区间,对于非常小的地理区域(如一个小镇),一年的样本量可能很小,估计结果会非常不稳定,可信度低,这时应优先使用5年期数据。
- 数据滞后性:即使是1年期数据,其发布也通常比数据所代表的年份晚一年多,2025年的1年期数据可能在2025年底才发布,这限制了政策评估的“实时性”。
- 变量定义的局限性:ACS的问卷是固定的,有时无法完美匹配政策的复杂定义,要精确识别“受益于某项税收抵免”的个人,可能需要结合税务数据,仅凭ACS数据很难做到。
- 无法追踪个体:ACS是横截面数据,它告诉你“在某一年,某个地方的人是什么样”,但无法告诉你“同一个人在政策前后的变化”,要追踪个体,需要结合其他纵向研究数据。
从ACS数据看政策执行情况,是一个将政策理论与实证数据相结合的系统工程,其核心在于:
- 精准定位:将政策目标转化为可量化的ACS指标。
- 科学比较:构建合理的处理组与控制组,使用DID等准实验方法剥离干扰。
- 理解语境:充分认识ACS数据的优势与局限,谨慎解读结果。
通过这种方法,决策者可以超越“政策出台了”的表面文章,深入探究“政策是否真正起作用了”、“谁从中受益了”、“效果有多大”等核心问题,从而实现更科学、
文章版权及转载声明
作者:99ANYc3cd6本文地址:https://bj-citytv.com/post/108.html发布于 2025-11-29
文章转载或复制请以超链接形式并注明出处北京城市TV