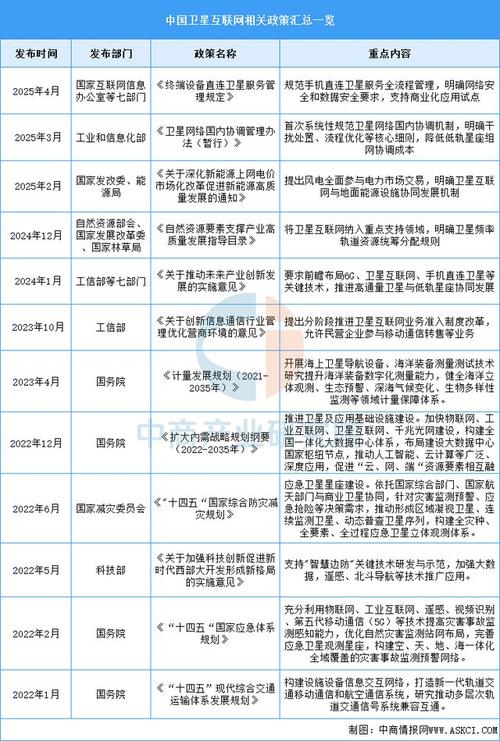
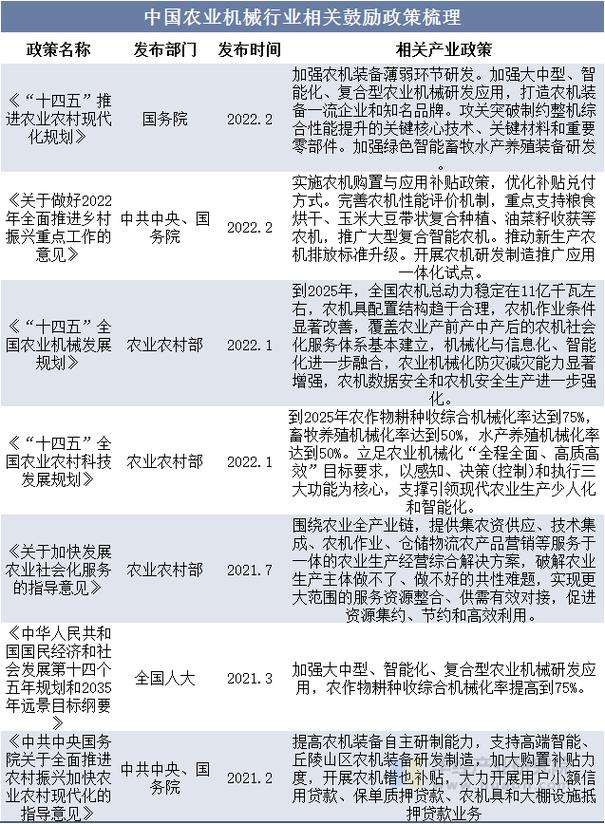
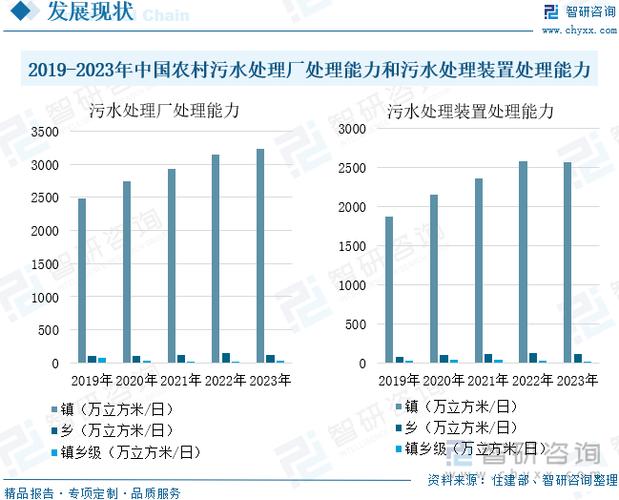
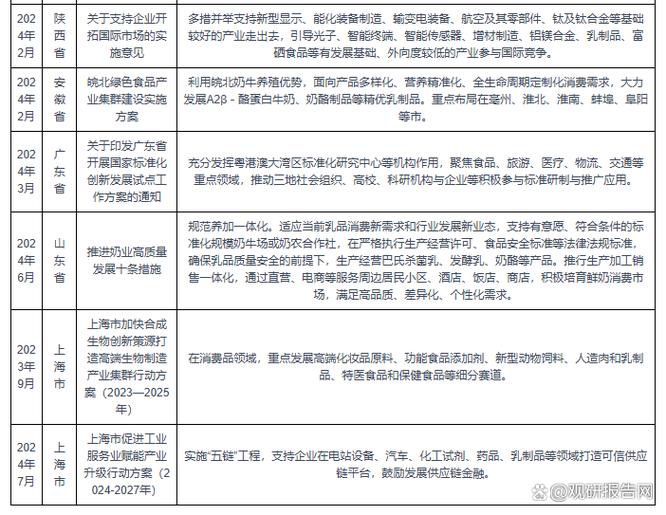
地级市产业政策数据库有何价值与局限?
 摘要:
项目目标与价值核心目标: 建立一个全面、准确、实时、可分析的全国地级市产业政策数据库,核心价值:对政府:政策对标: 横向对比各城市政策,优化自身政策体系,效果评估: 追踪政策落地效...
摘要:
项目目标与价值核心目标: 建立一个全面、准确、实时、可分析的全国地级市产业政策数据库,核心价值:对政府:政策对标: 横向对比各城市政策,优化自身政策体系,效果评估: 追踪政策落地效... 项目目标与价值
核心目标: 建立一个全面、准确、实时、可分析的全国地级市产业政策数据库。
(图片来源网络,侵删)
核心价值:
- 对政府:
- 政策对标: 横向对比各城市政策,优化自身政策体系。
- 效果评估: 追踪政策落地效果,评估投资回报率。
- 招商引资: 生成精准的政策“工具箱”,吸引目标企业。
- 对企业:
- 政策发现: 快速、精准地找到适用于自身发展的政策(如补贴、税收优惠、人才引进)。
- 合规与申报: 确保企业运营符合地方规定,并高效完成项目申报。
- 战略决策: 了解不同城市的产业导向和扶持力度,辅助选址、投资和扩张决策。
- 对研究机构/投资者:
- 量化分析: 进行区域经济、产业布局、政策效果等方面的量化研究。
- 尽职调查: 快速评估一个城市的产业环境和政策友好度。
- 风险预警: 监控政策变动,评估潜在的政策风险。
数据库核心内容设计
数据库的核心是结构化地存储产业政策信息,以下是一个建议的数据模型(字段设计):
政策基本信息表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
policy_id |
String (UUID) | 唯一标识符,主键 |
policy_title |
String | 政策官方全称 |
policy_short_title |
String | 政策简称或别名 |
issuing_authority |
String | 发布单位(如:XX市人民政府、XX市发改委) |
issuing_date |
Date | 发布日期 |
implementation_date |
Date | 实施日期 |
expiry_date |
Date | (重要) 政策失效日期 |
policy_status |
Enum (有效/失效/征求意见稿) | 政策当前状态,需定期更新 |
policy_type |
Enum | 政策类型(如:规划意见、管理办法、实施细则、资金申报指南) |
policy_level |
Enum | 政策层级(如:国家级、省级、市级、区县级) |
source_url |
String | 政策原文链接(来源官网) |
pdf_file_path |
String | 政策原文PDF文件的存储路径 |
全文表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
policy_id |
String (FK) | 关联到政策基本信息表 |
full_text |
Text | 政策的完整文本内容,用于全文检索和深度分析 |
政策核心要素/标签表(数据库的灵魂)
这是实现智能检索和分析的关键,需要通过自然语言处理和人工标注相结合的方式提取。
| 字段名 | 数据类型 | 说明 |
|---|---|---|
policy_id |
String (FK) | 关联到政策基本信息表 |
industry_focus |
Array of String | 核心产业领域(如:[“新一代信息技术”, “高端装备制造”, “生物医药”, “新能源”]) |
support_type |
Array of String | 支持类型(如:[“财政补贴”, “税收减免”, “用地保障”, “人才引进”, “融资支持”, “研发奖励”]) |
target_enterprise |
Array of String | 目标企业(如:[“高新技术企业”, “专精特新企业”, “独角兽企业”, “外资企业”, “中小企业”]) |
policy_tool |
Array of String | 政策工具(如:[“专项资金”, “贷款贴息”, “政府引导基金”, “风险补偿”, “项目评审”]) |
geographic_scope |
String | 适用地域(如:全市、XX高新区、XX经开区、特定园区) |
key_amount |
Array of JSON | 关键金额/比例(如:[{"type": "补贴上限", "value": "500万", "currency": "CNY"}, {"type": "税率", "value": "15%", "desc": "企业所得税"}]) |
key_requirement |
Array of String | 核心申请条件(如:[“营收达到1亿元以上”, “拥有发明专利5项以上”, “在本地注册并纳税”]) |
关联信息表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
city_id |
String | 城市唯一ID(关联城市信息库) |
policy_id |
String (FK) | 关联到政策基本信息表 |
related_policies |
Array of String | 相关政策ID(如:此政策的配套文件、更新版本等) |
数据库构建流程
-
数据采集
- 来源: 各地级市人民政府官网、发改委、科技局、人社局、财政局等部门的“政策文件”、“政府信息公开”、“通知公告”等栏目。
- 技术:
- 网络爬虫: 使用Python (Scrapy, Requests) + BeautifulSoup等技术,定期、自动化地抓取网页,难点在于处理反爬机制、动态加载内容和不同网站的页面结构差异。
- API接口: 部分政府开放数据平台会提供API,这是最稳定、最高效的数据来源。
-
数据清洗与预处理
- 去重: 基于标题、发布日期、发布单位等字段去除重复政策。
- 格式化: 将日期、金额等统一格式。
- 文本提取: 从HTML或PDF中提取纯文本内容。
-
信息抽取与结构化
- 这是最核心、技术难度最高的一步。
- 命名实体识别: 使用NLP模型(如BERT、BiLSTM+CRF)自动识别文本中的产业领域、支持方式、金额、企业类型、地域等关键实体。
- 关系抽取: 识别实体之间的关系,对XX产业的XX类型企业提供XX金额的XX支持”。
- 人工校验与标注: NLP模型无法做到100%准确,必须建立一个人工审核和校对的流程,确保标签的准确性,初期可以人工为主,后期逐步用模型辅助。
-
数据存储
- 关系型数据库: 如 PostgreSQL 或 MySQL,适合存储结构化的政策基本信息和关联信息,PostgreSQL对JSON/JSONB字段支持良好,适合存储
key_amount这类复杂数据。 - 搜索引擎: 如 Elasticsearch,用于构建强大的全文检索引擎,支持模糊搜索、关键词高亮、相关性排序等。
- 图数据库: 如 Neo4j,用于构建政策-城市-产业-企业之间的知识图谱,可以探索更深层次的关联,查看所有支持‘生物医药’产业且提供‘人才引进’政策的沿海城市”。
- 关系型数据库: 如 PostgreSQL 或 MySQL,适合存储结构化的政策基本信息和关联信息,PostgreSQL对JSON/JSONB字段支持良好,适合存储
-
数据更新与维护
- 自动化监控: 设置爬虫任务,定期(如每日)监控目标网站更新。
- 状态更新机制: 定期(如每季度)批量检查政策是否过期或被新政策替代,更新
policy_status字段。 - 用户反馈机制: 允许用户提交新政策或勘误,形成众包维护模式。
技术架构建议
- 前端: Vue.js / React.js,构建现代化的用户界面。
- 后端:
- API层: Python (Django/FastAPI) 或 Java (Spring Boot),提供RESTful API。
- 数据处理引擎: Python (Scrapy, NLP库如spaCy, HanLP)。
- 数据库:
- 主数据库: PostgreSQL (存储结构化数据)。
- 搜索引擎: Elasticsearch (提供搜索和分析能力)。
- 知识图谱: Neo4j (可选,用于高级分析)。
- 部署: Docker + Kubernetes (K8s) 实现容器化部署,保证可扩展性和稳定性,可以使用云服务(如阿里云、腾讯云、AWS)。
应用与功能展示
-
智能政策检索
- 多维度筛选: 用户可以按城市、产业、支持类型、企业类型、政策状态等任意组合进行筛选。
- 全文检索: 输入任意关键词(如“新能源汽车充电桩补贴”),返回相关政策。
- 政策对比: 用户可选择2-3条政策,进行并排对比,一目了然。
-
数据可视化与分析
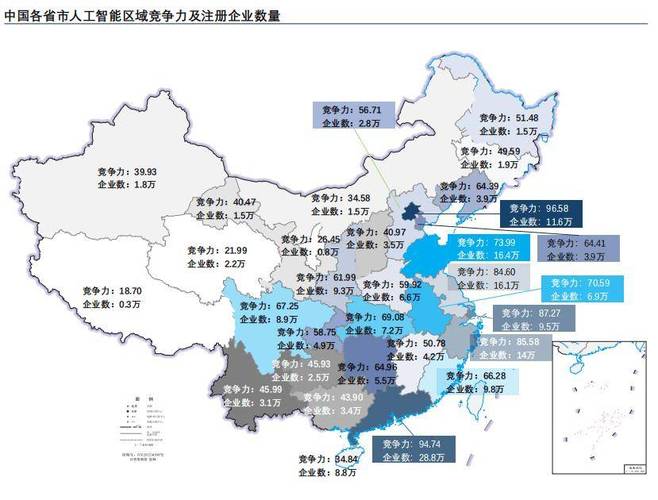
- 政策热力图: 在中国地图上展示各城市政策的数量或某一产业领域的支持力度。
- 趋势分析: 分析历年某类政策(如“人工智能”)的发布数量和金额变化趋势。
- 词云图: 展示当前政策文件中的高频关键词,反映政策焦点。
-
个性化推送与预警
- 订阅服务: 用户可以设置订阅条件(如:关注“苏州”市的“生物医药”政策),一旦有新政策匹配,系统自动发送邮件或站内信通知。
- 失效预警: 当用户收藏的政策即将到期时,系统提前发出预警。
-
API服务
将数据库能力封装成API,提供给第三方系统(如企业SaaS平台、政府内部系统)调用,实现数据赋能。
挑战与对策
- 挑战1:数据非结构化,质量参差不齐。
- 对策: 强大的NLP能力 + 人工审核流程相结合,建立数据质量评分体系。
- 挑战2:政策时效性强,更新维护成本高。
- 对策: 自动化监控 + 半自动化更新流程,将政策状态管理作为核心功能。
- 挑战3:政策解读的深度和准确性。
- 对策: 不仅仅是罗列条款,可以增加“政策解读”模块,由专家或AI生成摘要、要点提炼和申报指南。
- 挑战4:数据孤岛。
- 对策: 在设计之初就考虑API化和数据开放,鼓励生态伙伴基于数据进行二次开发。
构建这样一个数据库是一个系统工程,但一旦建成,将成为一个极具竞争力的战略资产,建议从一个试点区域(如长三角、珠三角)开始,逐步扩展到全国,以控制初期成本和复杂度。
文章版权及转载声明
作者:99ANYc3cd6本文地址:https://bj-citytv.com/post/3501.html发布于 01-08
文章转载或复制请以超链接形式并注明出处北京城市TV