信息抽取技术前景如何?
 摘要:
信息抽取技术浅析 什么是信息抽取?—— 从“数据海洋”到“知识金矿”想象一下,你面对的是互联网上浩如烟海的文本数据——新闻、报告、社交媒体、科研论文、合同文档等,这些数据是人类知识...
摘要:
信息抽取技术浅析 什么是信息抽取?—— 从“数据海洋”到“知识金矿”想象一下,你面对的是互联网上浩如烟海的文本数据——新闻、报告、社交媒体、科研论文、合同文档等,这些数据是人类知识... 信息抽取技术浅析
什么是信息抽取?—— 从“数据海洋”到“知识金矿”
想象一下,你面对的是互联网上浩如烟海的文本数据——新闻、报告、社交媒体、科研论文、合同文档等,这些数据是人类知识的载体,但它们是非结构化或半结构化的,机器难以直接理解和利用。
信息抽取就是一门技术,它的目标是从这些非结构化文本中,自动识别并抽取出结构化信息的过程,就是让机器学会“阅读”和“理解”文本,并将其转化为机器可读、可计算的知识形式。
打个比方:
- 原始文本(非结构化): “张三,男,35岁,是北京字节跳动科技有限公司的一名高级软件工程师,他毕业于北京大学计算机科学系。”
- 信息抽取(结构化):
- 实体:
张三(人名),北京字节跳动科技有限公司(机构),北京大学计算机科学系(机构) - 关系:
(张三, 毕业于, 北京大学计算机科学系),(张三, 任职于, 北京字节跳动科技有限公司) - 属性:
张三的性别是男,年龄是35,职位是高级软件工程师。
- 实体:
通过IE技术,一段杂乱的文字就变成了结构化的知识三元组,可以被存入知识图谱、数据库,供下游应用(如智能问答、推荐系统)使用。
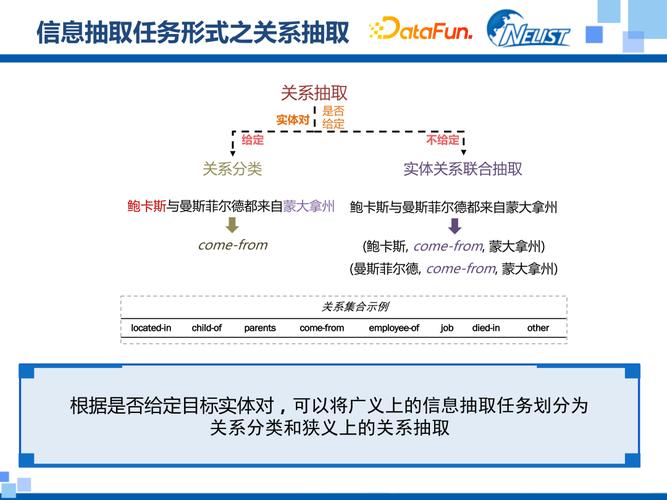
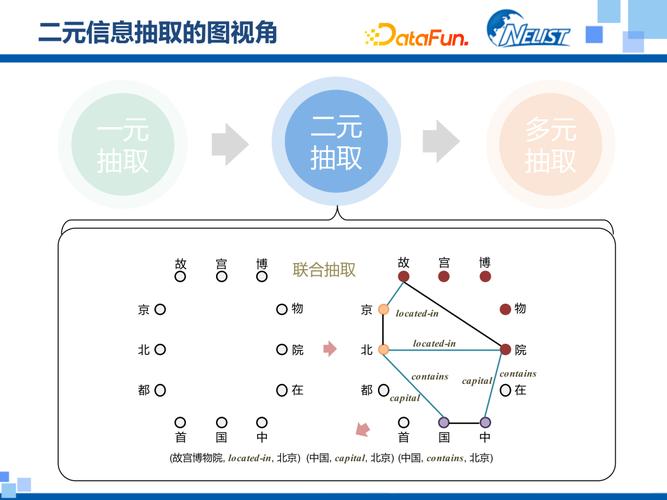
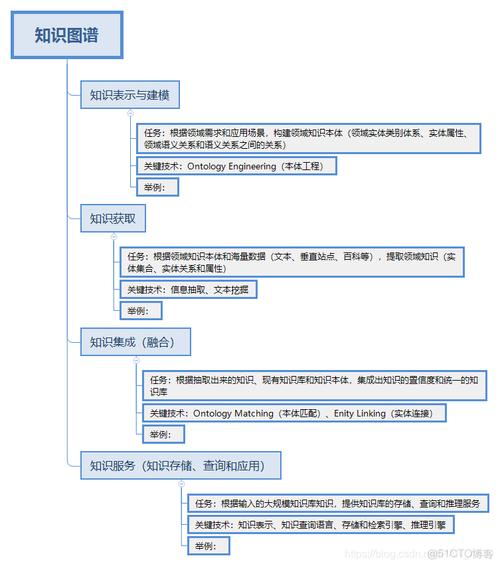
核心技术模块—— IE的“三板斧”
信息抽取通常包含几个核心任务,它们层层递进,共同构成了IE的技术栈。
-
命名实体识别
- 目标: 识别文本中具有特定意义的实体,并将其分类到预定义的类别中。
- 常见类别:
- 人物: 如“马云”
- 地点: 如“上海”
- 组织机构: 如“阿里巴巴”
- 时间/日期: 如“2025年10月1日”
- 专有名词: 如“iPhone 15”、“新冠”
- 技术演进: 从早期的规则、统计模型(如HMM、CRF)到如今基于深度学习的模型(如BiLSTM-CRF、BERT及其变体),NER的准确率得到了巨大提升。
-
关系抽取
- 目标: 识别实体之间存在的语义关系。
- 示例: 在句子“苹果公司总部位于美国加州库比蒂诺”中,抽取关系
(苹果公司, 总部位于, 美国加州库比蒂诺)。 - 主要方法:
- 监督学习: 需要大量标注数据,效果最好但成本高。
- 远程监督: 利用现有知识库(如Freebase)自动生成训练数据,但会引入噪声。
- 弱监督/无监督: 通过模式匹配、开放信息抽取等技术减少对标注数据的依赖。
-
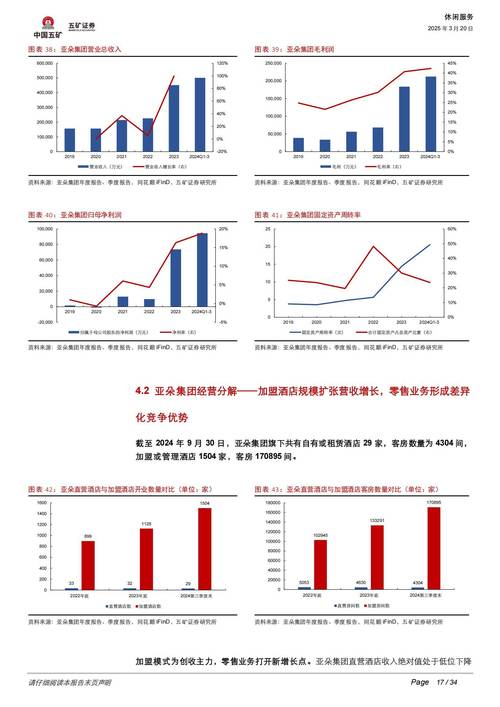
事件抽取
- 目标: 识别文本中描述的事件,并提取事件的触发词、参与者(事件元素)以及它们之间的角色。
- 示例: 在新闻“王伟在昨天收购了A公司”中,识别出“收购”事件,并提取:
- 触发词: 收购
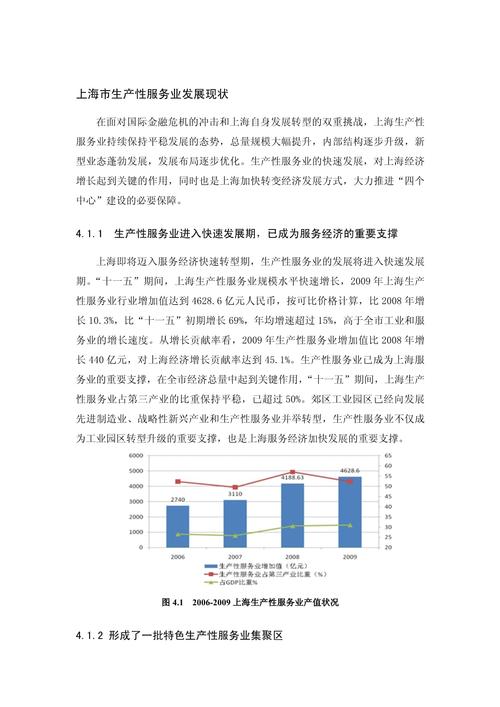
- 收购者: 王伟
- 被收购方: A公司
- 时间: 昨天
- 挑战: 事件的结构复杂多样,需要模型具备更强的语义理解能力。
-
属性抽取
 (图片来源网络,侵删)
(图片来源网络,侵删)- 目标: 提取实体的特定属性信息。
- 示例: 对于实体“特斯拉”,抽取其属性
创始人:马斯克、成立时间:2003年、总部:美国加州。
主要应用领域—— IE技术的“用武之地”
信息抽取是连接原始文本数据与高级智能应用的桥梁,其应用极其广泛。
-
知识图谱构建
- 核心应用: IE是自动化构建大规模知识图谱(如Google Knowledge Graph)的核心技术,通过持续从互联网、文献中抽取实体、关系和事件,不断丰富和更新知识图谱,为搜索引擎、智能问答提供知识支撑。
-
智能问答与对话系统
- 应用: 当用户问“《流浪地球2》的导演是谁?”,系统首先需要用IE技术从相关文本中抽取出
(《流浪地球2》, 导演, 郭帆)这个三元组,然后生成答案“郭帆”,对于更复杂的对话,IE能帮助系统理解用户意图中的关键信息。
- 应用: 当用户问“《流浪地球2》的导演是谁?”,系统首先需要用IE技术从相关文本中抽取出
-
金融风控与舆情分析
- 金融: 从上市公司的年报、公告中自动抽取财务数据、高管变动、重大合同等信息,辅助投资决策和风险预警。
- 舆情: 从社交媒体、新闻中抽取关于某个品牌或产品的评价观点(情感)、提及的关键事件,实时监控市场舆情。
-
生物医药领域
- 应用: 从海量的医学文献、临床试验报告中,抽取基因、蛋白质、疾病、药物之间的相互作用关系,加速新药研发和疾病机理研究。
-
法律与合规
- 应用: 从冗长的法律合同中自动提取关键条款(如甲方、乙方、金额、生效日期、违约责任),大幅提高合同审查效率和准确性。
面临的挑战与局限—— IE的“成长烦恼”
尽管IE技术取得了巨大进步,但在实际应用中仍面临诸多挑战。
-
领域适应性差
- 问题: 在某个领域(如金融新闻)训练好的模型,直接应用到另一个领域(如生物医学文献)上,性能会急剧下降,这主要是因为不同领域的术语、表达方式和关系模式差异巨大。
- 对策: 领域自适应、小样本学习、提示学习是当前的研究热点。
-
对复杂句式和隐含关系的理解不足
- 问题: 当前模型(尤其是基于BERT的)在处理长文本、复杂嵌套句式时效果不佳,对于文本中没有明确陈述、需要推理才能得出的关系,抽取能力很弱。
- 示例: “作为苹果公司的前CEO,乔布斯的影响力至今无人能及。” 这里需要推理出
(乔布斯, 曾任职于, 苹果公司),这对模型是巨大挑战。
-
数据标注成本高昂
- 问题: 监督学习模型需要大量高质量的人工标注数据,而标注过程耗时耗力,且需要专业知识,成为工业界应用的一大瓶颈。
-
可解释性差
- 问题: 深度学习模型像一个“黑箱”,我们往往知道它抽出了什么,但很难理解它为什么这么抽,这在金融、医疗等高风险领域是不可接受的。
未来前景与趋势—— IE的“星辰大海”
面向未来,信息抽取技术将朝着更智能、更通用、更高效的方向发展。
-
与大语言模型的深度融合
- 趋势: 以GPT-4、LLaMA为代表的大语言模型展现了强大的零样本/小样本学习能力和世界知识,未来的IE系统将不再是一个个孤立的模型,而是以LLM为核心,通过精心设计的提示来引导模型完成复杂的抽取任务。
- 优势: 大大降低了对标注数据的依赖,提升了模型处理复杂和隐含关系的能力,并具备一定的推理能力。
-
从抽取到生成
- 趋势: 传统的IE是“抽取式”的,从文本中找出已有信息,而基于LLM的“生成式”信息抽取,可以根据需求直接生成自然语言描述的结构化信息,甚至进行信息补全和推理,形式更加灵活。
-
多模态信息抽取
- 趋势: 信息不再只存在于文本中,未来的IE将能够同时处理文本、图像、表格、音频等多种模态的信息,并进行跨模态的联合理解与抽取,从一份包含图片和文字的报告中,同时抽取表格数据和图片中的实体。
-
自动化与持续学习
- 趋势: 系统能够自动发现新的实体类型和关系模式,并持续从新数据中学习,实现自我迭代和更新,以适应不断变化的世界知识。
-
可信赖与负责任的AI
- 趋势: 随着IE技术在关键领域的应用,其公平性、鲁棒性和可解释性将变得至关重要,研究如何减少模型偏见、确保抽取结果的可靠性,将是未来的重要方向。
信息抽取是自然语言处理领域的一项基础且关键的技术,它如同一位不知疲倦的“知识矿工”,从非结构化的数据海洋中挖掘出结构化的知识金矿,为人工智能的智能化应用提供了核心燃料。
当前,IE技术正站在一个由传统深度学习向大语言模型时代跨越的十字路口,虽然挑战犹存,但其在知识图谱、智能问答、金融风控等领域的巨大价值已毋庸置疑,随着与大语言模型的深度融合,信息抽取将变得更加智能、通用和强大,必将在推动AI产业升级和赋能各行各业方面发挥越来越重要的作用。
作者:99ANYc3cd6本文地址:https://bj-citytv.com/post/1074.html发布于 2025-12-12
文章转载或复制请以超链接形式并注明出处北京城市TV