cpu的组成现状以及发展趋势
 摘要:
这是一个非常宏大且快速演进的话题,我们可以将其分为两大部分:现状和趋势,第一部分:CPU的组成现状现代CPU已经不再是简单的“中央处理器”,而是一个极其复杂的“系统级芯片”(Sys...
摘要:
这是一个非常宏大且快速演进的话题,我们可以将其分为两大部分:现状和趋势,第一部分:CPU的组成现状现代CPU已经不再是简单的“中央处理器”,而是一个极其复杂的“系统级芯片”(Sys... 这是一个非常宏大且快速演进的话题,我们可以将其分为两大部分:现状和趋势。
(图片来源网络,侵删)
第一部分:CPU的组成现状
现代CPU已经不再是简单的“中央处理器”,而是一个极其复杂的“系统级芯片”(System on a Chip, SoC)的核心,或者是一个高度集成的“封装系统”(System in Package, SiP),其组成可以从物理结构和功能架构两个维度来理解。
物理结构现状
-
制造工艺:
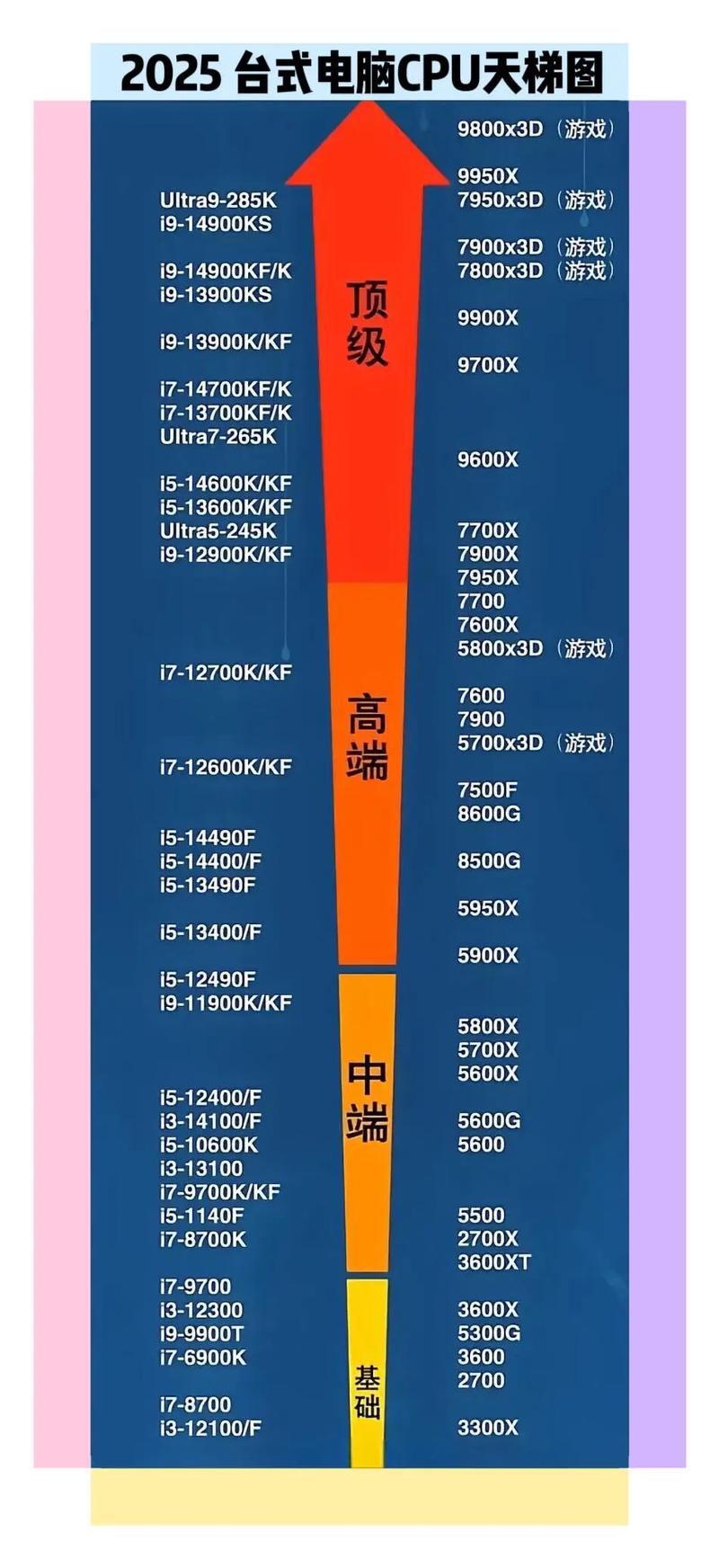
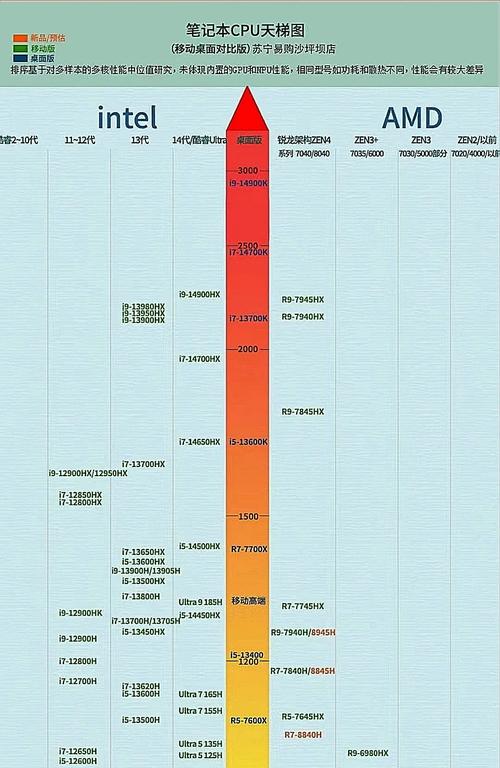
- 主流节点: 消费级和主流服务器CPU的制造工艺已经进入5纳米和3纳米时代,苹果的M3系列、AMD的Ryzen 7000系列(基于台积电5nm/4nm)以及Intel的酷睿Ultra系列(Intel 7/4nm)。
- 晶体管密度: 更小的工艺意味着可以在同样大小的芯片上集成更多的晶体管,苹果M3 Max芯片集成了1340亿个晶体管,这为提升性能和能效比提供了基础。
- 挑战: 3nm及以下工艺面临着量子隧穿效应、散热、成本急剧上升等物理和经济极限的挑战。
-
核心架构:
- 异构计算: 这是当前最核心的架构特征,一个CPU芯片内部不再只有同一种类型的核心,而是集成了多种核心,以应对不同负载的需求。
- 性能核: 负责处理对性能要求最高的任务,如大型游戏、视频编辑、科学计算,追求高频率和强大的单核性能。
- 能效核: 负责处理后台任务、日常应用和轻负载工作,追求极致的能效,以延长笔记本电池续航或在服务器中降低功耗。
- 专用核心: 部分高端CPU还集成了AI加速器(如Apple的Neural Engine、Intel的NPU)、图像信号处理器、视频编解码引擎等专用硬件,以高效处理特定任务。
- 核心数量: 核心数量持续增加,消费级CPU从4核、6核发展到8核、12核甚至24核(如AMD Ryzen 9 7950X),服务器CPU核心数量则可达64核、96核甚至更多。
- 异构计算: 这是当前最核心的架构特征,一个CPU芯片内部不再只有同一种类型的核心,而是集成了多种核心,以应对不同负载的需求。
-
封装技术:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 先进封装: 由于单芯片集成所有晶体管变得困难,先进封装技术成为关键,它将多个不同功能的“芯片let”(Chiplet)封装在一个基板上,实现高性能、高带宽和低成本。
- 代表技术:
- AMD的3D V-Cache: 将巨大的L3缓存堆叠在CPU核心之上,极大提升了游戏和某些应用的性能。
- Intel的Foveros和EMIB: 实现芯片的3D堆叠和2D异集成,将CPU、GPU、I/O等功能模块封装在一起。
- 台积电的CoWoS: 广泛应用于高性能计算和AI芯片,如NVIDIA的GPU。
功能架构现状
-
执行单元:
- 超标量乱序执行: 现代CPU可以在一个时钟周期内启动多条指令,并通过乱序执行技术,尽可能让CPU的各个执行单元(整数、浮点、内存加载/存储)保持忙碌,从而最大化性能。
- SIMD(单指令多数据): 通过向量处理单元,一条指令可以同时处理多个数据,AVX-512指令集可以一次性处理512位的数据,广泛应用于科学计算、AI和媒体处理。
-
缓存:
- 三级缓存架构: 几乎所有现代CPU都采用L1、L2、L3三级缓存结构。
- L1 Cache: 最小最快,分为数据缓存和指令缓存,紧挨着核心。
- L2 Cache: 容量和速度介于L1和L3之间,通常每个核心独享。
- L3 Cache: 最大最慢,所有核心共享,用于减少访问主内存的次数,是提升多核性能的关键,AMD的3D V-Cache技术就是将L3 Cache做到了极致。
- 三级缓存架构: 几乎所有现代CPU都采用L1、L2、L3三级缓存结构。
-
内存控制器:
- 集成式内存控制器: 内存控制器已经集成在CPU内部,而不是像早期那样位于主板上,这大大降低了CPU与内存之间的延迟。
- 内存类型: 主流是DDR5,提供更高的带宽和更低的功耗。LPDDR5/LPDDR5X广泛用于移动设备,以实现低功耗和高性能。
-
互联总线:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 片上网络: 在CPU内部,各个核心、缓存、I/O控制器之间通过一个复杂的、类似网络的互联总线进行通信,以解决数据传输的瓶颈问题。
-
集成显卡:
对于非专业图形用户,CPU内部集成的GPU(核显)已成为标配,Intel的 Iris Xe、AMD的 Radeon Graphics 性能越来越强,足以应对日常办公、高清视频播放和部分轻度游戏。
第二部分:CPU的发展趋势
面对性能瓶颈、功耗墙以及新的应用需求(如AI、大数据),CPU的发展呈现出以下几个明确的趋势:
架构持续异构化与专用化
- 趋势描述: 未来的CPU将更像一个“任务调度中心”,而不是一个“全能选手”,它会集成更多类型的、功能更专一的核心和加速单元。
- 具体表现:
- AI核心/NPU的普及: 人工智能计算将成为所有计算设备的标准配置,NPU(神经网络处理单元)将从高端芯片下放到主流消费级CPU,用于本地AI推理,如实时翻译、图像生成、智能助手等,以减轻CPU和GPU的负担。
- 可配置/可定制计算: 类似于RISC-V的理念,未来可能会出现更多可配置的硬件单元,允许软件根据需求动态调整硬件功能,以获得最佳能效比。
制造工艺的极限探索与新材料
- 趋势描述: 摩尔定律虽然放缓,但技术创新并未停止,工艺发展的重点将从单纯缩小尺寸转向三维集成和新材料应用。
- 具体表现:
- Chiplet(小芯片)与先进封装: 这将是未来5-10年的绝对主流,通过将不同工艺、不同功能的Chiplet(如CPU核心、I/O、内存控制器、AI加速器)封装在一起,可以绕过单芯片制造的物理极限,实现更高的良率、更灵活的设计和更低的成本。
- 3D堆叠: 像AMD的3D V-Cache一样,将不同层次的芯片垂直堆叠,是突破平面面积限制的关键。
- 新材料: 硅基材料接近物理极限,碳纳米管、二维材料(如二硫化钼)、光子互联(用光代替电信号传输数据,速度更快、能耗更低)等新材料和技术正被积极探索,有望在未来10-20年内带来颠覆性变革。
通用计算与专用计算的深度融合
- 趋势描述: CPU、GPU、FPGA、ASIC等不同类型的计算单元之间的界限将变得模糊,它们将通过统一的软件平台(如CUDA、SYCL)协同工作,形成“计算统一设备架构”。
- 具体表现:
- CPU+GPU的协同: 这已是常态,未来将是CPU+NPU+GPU的更紧密协同,CPU负责通用任务和调度,NPU负责AI任务,GPU负责图形和并行计算。
- 软件定义硬件: 编译器和操作系统将变得更智能,能够自动将任务分配给最合适的硬件单元,最大化整个系统的能效和性能。
专注于能效比与可持续发展
- 趋势描述: “性能每瓦”(Performance per Watt)的重要性已经超过单纯的“绝对性能”,随着数据中心和移动设备的能耗问题日益突出,能效比成为CPU设计的首要考量。
- 具体表现:
- 硬件层面: 持续优化核心架构,引入更多能效核,并利用Chiplet技术关闭不工作的部分以降低功耗。
- 软件层面: 操作系统(如Windows的异构调度)和应用将更好地利用异构核心,智能分配任务。
- 可持续发展: 降低芯片的制造和运行功耗,不仅是技术问题,也是社会责任,芯片厂商会公布产品的碳足迹,并致力于使用绿色能源。
存算一体
- 趋势描述: 这是解决“内存墙”(CPU速度远快于内存访问速度)的终极方案之一,它将计算单元直接嵌入到存储器中,或者在存储单元内部进行计算,从而消除数据搬运带来的巨大延迟和功耗。
- 具体表现:
- 应用场景: 特别适合处理大规模数据,如数据库、大数据分析、AI模型训练等。
- 发展阶段: 目前仍处于早期研究和商业化探索阶段,但被认为是后摩尔时代最重要的技术方向之一。
| 方面 | 现状 | 未来趋势 |
|---|---|---|
| 核心架构 | 异构计算(性能核+能效核)成为标配 | 深度异构化,集成更多专用核心(如NPU),任务调度更智能 |
| 物理实现 | 5nm/3nm工艺,单芯片集成极限 | Chiplet + 先进封装成为主流,3D集成广泛应用 |
| 性能追求 | 追求高频率、多核心、大缓存 | 从“绝对性能”转向“性能/能效比”,可持续发展是关键 |
| 计算模式 | CPU、GPU、NPU初步协同 | 通用与专用计算深度融合,形成统一的异构计算平台 |
| 内存瓶颈 | 依赖多级缓存和集成内存控制器 | 存算一体等颠覆性技术有望从根本上解决“内存墙”问题 |
| 互联方式 | 高速片上总线 | 光子互联等新技术提供更高带宽、更低延迟的通信 |
CPU的未来将不再是单打独斗的“孤胆英雄”,而是一个高度协同、分工明确、智能调度的“计算系统大脑”,其发展将不再仅仅遵循摩尔定律的节奏,而是架构、工艺、材料和软件协同创新的共同结果,最终目标是构建一个更强大、更高效、更智能的计算平台。
文章版权及转载声明
作者:99ANYc3cd6本文地址:https://bj-citytv.com/post/617.html发布于 2025-12-06
文章转载或复制请以超链接形式并注明出处北京城市TV